redis设计与实现系列1-SDS
1. SDS的定义
redis没有直接使用c语言的传统字符串表示(以空字符结尾的字符数组),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型。
redis关于SDS的实现在 sds.h和 sds.c文件中。sds的结构体定义是:
/*
* 保存字符串对象的结构
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};
其中 len字段记录buf数组中已经使用字节的数量,等于SDS所保存字符串的长度;free记录了 buf数组中未使用的字节的数量;buf就是字节数组,用来保存字符串的。
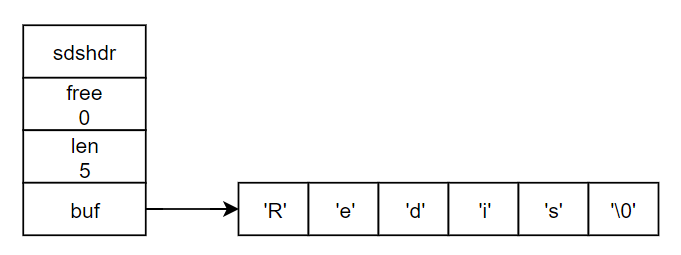
如图所示,代表了一个简单的SDS,free属性的值为0,表示这个SDS没有分配任何未使用的空间。len属性为5,表示这个SDS保存了一个5字节长的字符串。buf属性是一个char类型的数组,数组的前五个字节分别保存了 'B','i','t','b','o'五个字符,而最后一个字节则保存了空字符 '\0'。
可见,SDS遵循c字符串以空字符结尾的惯例,保存空字符的一字节空间不计算在SDS的 len属性里面,并且为空字符分配额外的一字节空间。这样做的好处是SDS可以直接重用部分c字符串函数库里面的函数,比如用来比较字符串的 <string.h>/strcasecmp函数。
SDS的初始化:
/*
* 根据给定的初始化字符串 init 和字符串长度 initlen 创建一个新的 sds
*
* 参数
* init :初始化字符串指针
* initlen :初始化字符串的长度
*
* 返回值
* sds :创建成功返回 sdshdr 相对应的 sds
* 创建失败返回 NULL
*
* 复杂度
* T = O(N)
*/
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
// 根据是否有初始化内容,选择适当的内存分配方式
// T = O(N)
if (init) {
// zmalloc 不初始化所分配的内存
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
// zcalloc 将分配的内存全部初始化为 0
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
// 内存分配失败,返回
if (sh == NULL) return NULL;
// 设置初始化长度
sh->len = initlen;
// 新 sds 不预留任何空间
sh->free = 0;
// 如果有指定初始化内容,将它们复制到 sdshdr 的 buf 中
// T = O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 以 \0 结尾
sh->buf[initlen] = '\0';
// 返回 buf 部分,而不是整个 sdshdr
return (char*)sh->buf;
}
2. SDS与c字符串的区别
2.1 常数复杂度获取字符串的长度
这一点对于习惯了面向对象、使用高级语言的开发人员来说应该非常亲切。就是类似一个对象里面的一个属性,这个属性记录了这个字符串对象的长度。因为传统c语言中,如果要知道一个字符串数组的长度,都需要去遍历字符串,利用空字符串来判断长度,时间复杂度是O(N),但是这样包装一下,每次对字符串增加或者截短的时候改变一下这个属性,就能达到O(1)时间复杂度获取字符串长度的效果。
2.2 杜绝缓冲区溢出
c语言不记录自身长度带来的另一个问题是容易造成缓冲区溢出(buffer overflow)。比如在一块内存中,紧挨着两个字符串 bitbo和 code,这样 bitbo和 code会有一个空字符,如果此时使用一个字符串拼接函数 <string.h>/strcat来在 bitbo后面追加字符串 redis,那么 code字符串就会被覆盖,修改。
但是如果使用SDS,那么每次操作字符串的时候都会去检查当前SDS的空间是否满足修改,不够就申请内存,扩展空间。
2.3 减少修改字符串时的内存重分配次数
因为每次增长或者缩短一个C字符串,程序都要对保存这个C字符串的数组进行一次内存重分配,而内存重分配涉及复杂的算法,并且可能需要执行系统调用,所以它通常是一个比较耗时的操作,为了避免C字符串的这种缺陷,SDS就通过未使用空间解除了字符串和底层数组长度之间的关联:在SDS中,buf数组的长度不一定就是字符数量加一,数组里面可以包含未使用的字节,而这些字节的数量就由SDS的free属性记录。通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略。
2.3.1 空间预分配
空间预分配用于优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所需要的空间,还会为SSDS分配额外的未使用空间。比如:
- 如果SDS进行修改之后,SDS的长度(
len字段)小于1MB,比如13,那么会分配和len属性同样大小的空间,这时候SDS的buf数组的实际长度就变成13 + 13 + 1(额外的一字节用于保存空字符)。 - 但是如果SDS的长度大于1MB,那么程序就只会分配1MB的空间,也就是
30MB + 1MB + 1byte
这里逻辑的实现就是 sdsMakeRoomFor函数里面:
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
// s 最少需要的长度
newlen = (len+addlen);
// 根据新长度,为 s 分配新空间所需的大小
if (newlen < SDS_MAX_PREALLOC)
// 如果新长度小于 SDS_MAX_PREALLOC
// 那么为它分配两倍于所需长度的空间
newlen *= 2;
else
// 否则,分配长度为目前长度加上 SDS_MAX_PREALLOC
newlen += SDS_MAX_PREALLOC;
...
// 返回 sds
return newsh->buf;
}
字符串的追加:
/*
* 将长度为 len 的字符串 t 追加到 sds 的字符串末尾
*
* 返回值
* sds :追加成功返回新 sds ,失败返回 NULL
*
* 复杂度
* T = O(N)
*/
sds sdscatlen(sds s, const void *t, size_t len) {
struct sdshdr *sh;
// 原有字符串长度
size_t curlen = sdslen(s);
// 扩展 sds 空间
// T = O(N)
s = sdsMakeRoomFor(s,len);
// 内存不足?直接返回
if (s == NULL) return NULL;
// 复制 t 中的内容到字符串后部
// T = O(N)
sh = (void*) (s-(sizeof(struct sdshdr)));
memcpy(s+curlen, t, len);
// 更新属性
sh->len = curlen+len;
sh->free = sh->free-len;
// 添加新结尾符号
s[curlen+len] = '\0';
// 返回新 sds
return s;
}
2.3.2 惰性空间释放
惰性空间释放用于优化SDS的字符串缩短操作:当SDS的API需要缩短SDS保存的字符串时候,程序并不会立即使用内存重分配来回收缩短后多出来的字节,而是使用 free属性将这些字节的数量记录起来,并等待将来使用。
比如 sdstrim函数,只是修改 free和 len属性值:
/*
* 对 sds 左右两端进行修剪,清除其中 cset 指定的所有字符
*
* 比如 sdsstrim(xxyyabcyyxy, "xy") 将返回 "abc"
*
* 复杂性:
* T = O(M*N),M 为 SDS 长度, N 为 cset 长度。
*/
sds sdstrim(sds s, const char *cset) {
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
char *start, *end, *sp, *ep;
size_t len;
// 设置和记录指针
sp = start = s;
ep = end = s+sdslen(s)-1;
// 修剪, T = O(N^2)
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > start && strchr(cset, *ep)) ep--;
// 计算 trim 完毕之后剩余的字符串长度
len = (sp > ep) ? 0 : ((ep-sp)+1);
// 如果有需要,前移字符串内容
// T = O(N)
if (sh->buf != sp) memmove(sh->buf, sp, len);
// 添加终结符
sh->buf[len] = '\0';
// 更新属性
sh->free = sh->free+(sh->len-len);
sh->len = len;
// 返回修剪后的 sds
return s;
}
2.4 二进制安全
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能含有空字符,会被认为是字符串结尾,所以C字符串只能保存文本数据,不能保存像图片、音视频等二进制数据。但是使用SDS就能保证安全,因为SDS是使用len属性来判断字符串是否结束。
所以SDS的 buf属性被称为字节数组,因为这个数组不是用来存字符串的,而是用来存一系列二进制数据的。
2.5 兼容部分C字符串函数
SDS遵循C字符串以空字符结尾的惯例,这样可以重用一些 <string.h>库里面定义的函数。
2.6 总结
| C字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度是O(n) | 获取字符串长度的复杂度是O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
可以使用所有 <string.h>库里面定义的函数。 |
可以使用一部分 <string.h>库里面定义的函数。 |